- OCRopus - Open Source Layout Analysis and OCR
- Screen OCRopus
- Camera-based document capture (iDesk)
- StereoBook
- Document Browser
- Visual document similarity search (FireWatch)
- Document Image Dewarping
- One-step capture and restoration (OSCAR)
- Geometric Layout Analysis
- Document Images to HTML
- Comparison of Layout Analysis Techniques
- Performance Evaluation of Layout Analysis Techniques
- Geometric Matching for Arc and Line Finding
- Patch-Based Object Recognition Using Geometric Matching
- Document Image Retrieval based on Layout Similarity
- Page Frame Detection
- Document image viewing and retrieval based on special OCR (DIVER)
- Image Browser
- Bibliographic meta-data extraction using PFST.
- Accessibility Proxy
- Image-Based HTML Layout Verifier
|
| |
OCRopus - Open Source Layout Analysis and OCR
To make the contents of books and other documents searchable and accessible, they need to be transformed into machine readable text, and the layout and markup of the pages need to be analyzed. Collectively, these two operations are carried out by Optical Character Recognition (OCR) systems. OCR appears to be a mature field, with many decades of research by numerous research groups invested in it. However, current commercial OCR systems still have a number of limitations for practical applications.
With OCRopus, the Image Understanding and Pattern Recognition Group (IUPR) at the German Research Center for Artificial Intelligence (DFKI) is developing an adaptive and adaptable open source OCR system for both desktop use and high-volume conversion efforts. The system incorporates state-of-the-art pattern recognition, statistical natural language processing, and image processing methods.
The goals of the project are to advance the state-of-the-art in optical character recognition and related technologies, and to deliver a high quality OCR system suitable for document conversions, electronic libraries, vision impaired users, historical document analysis, and general desktop use. Unlike previous systems, we are structuring Ocropus in such a way that it will be easy to reuse by other researchers in the field. We are releasing OCRopus under the Apache 2 license with the initial release for English only, combining the Tesseract character recognizer with DFKI layout analysis. The technology preview release is downloadable from: http://www.ocropus.org/
In addition to the efforts at DFKI to advance OCRopus, we are hoping for contributions by the open source community, for example by adapting the system to additional languages.
|
|
The demo of Open Source Layout Analysis and OCR allows you to upload a scanned document image and the system will return the editable text.
|

Screenshot of OCRopus
|
| [Back to Top] |
Screen OCRopus
Screen OCRopus is an application of OCRopus for reading screen-rendered text. Screen-rendered text poses major challenges to OCR due to very small font size, font antialiasing, and the rich use of colors. OCRopus can read the screen text quite reliably. We have developed a GUI based interface to allow capturing regions from the screen and feeding them to OCRopus. A screenshot of the GUI is shown in the Figure below.
|
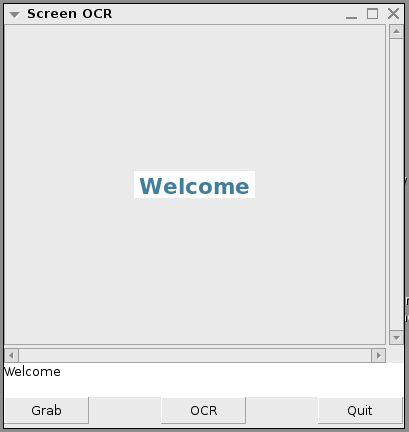
Screenshot of Screen-OCR and GUI of the application. |
| Back to Top |
Camera-based document capture (iDesk)
The iDesk demonstrator is designed to be a real desk in order to show how it helps bridge
the gap from the off-line to the on-line desktop. A standard digital photo camera is mounted
on top of the iDesk to observe the user's desktop. The low-resolution image of the viewfinder
is processed in real-time to detect documents in the field of view. As soon as a document is
detected, a high-resolution image is acquired and the document image extracted. Several digital
cameras were tested and currently a 7 Megapixel Canon Powershot A 620 serves as the input
device, because of all cameras supporting the PTP-protocol used to remotely access the cameras
functionality, it offers the highest image quality.
It is a key feature of the demonstrator that there is no need for the user to do anything
else than placing a document on the desk in order to capture an image of it. Additionally, the
region where to place the document is not restricted. This enables a seamless integration into
the user's interaction with documents and no additional effort is required to obtain a digital
version of the currently read content.
This demonstrator can be seen as a central application in our set of tools. Since it converts
paper documents into digital document images it serves as a starting point for many other
demonstrators. One of the possible integration steps is immediately visible, as the GUI of the
demonstrator offers an option to perform layout analysis on the captured document image.
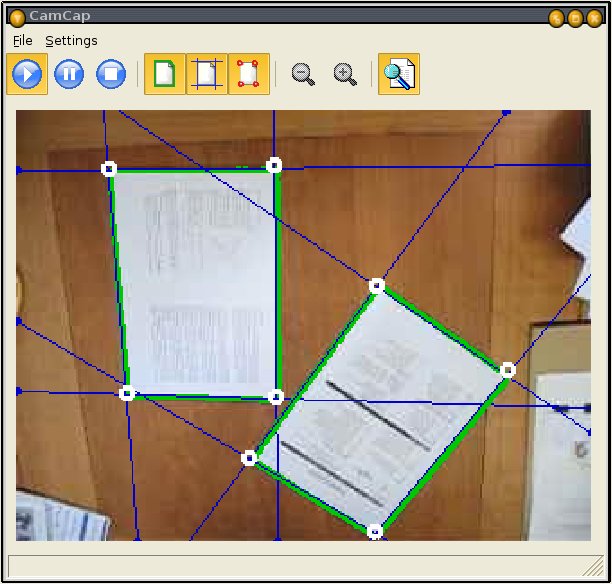
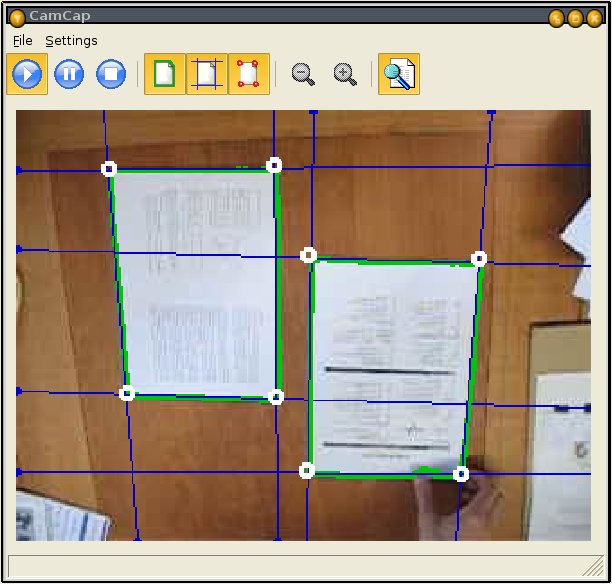
Figure shows the setup of the iDesk demonstrator and its graphical user interface.
The iDesk was presented to a wide audience with industrial background at the 7th E12-Summit
"Digital Living" (Munich, December 2005) and to a scientific audience at the International
Workshop on Camera-Based Document Analysis and Recognition (Seoul, August 2005).
The demonstrator has been improved with respect to the algorithms for detecting documents
as well as user interaction aspects. It is now possible to detect a document without doing any
previous calibration steps. The speed of all processing steps and accordingly the frame rate has
been significantly increased. In addition, the demonstrator now can zoom in to the maximum
zoom level that still contains the entire detected document in order to capture it in the maximum
possible resolution. These improvements all lead to a better user experience. Furthermore, the
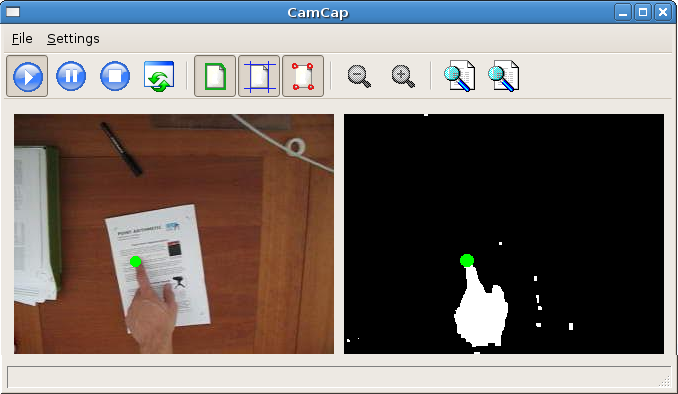
system has been extended to detect the hand of a user on top of a document as shown in Figure.
With this seamless way of human computer interaction, the user is now able to point with his
fingertip at a certain region of interest in a document, which can then be further processed.
|

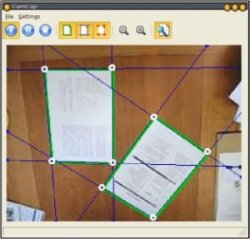
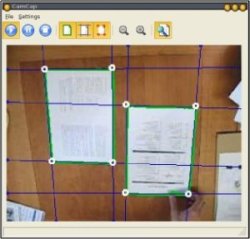
iDesk demonstrator setup and visualization GUI of the camera-based capture process. |
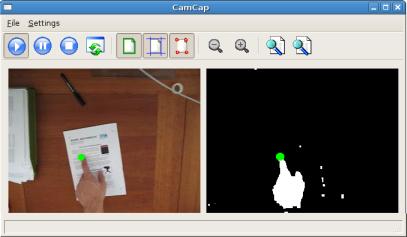
Detection of the fingertip of a user pointing at a region of interest in a document.
|
| [Back to Top] |
StereoBook
A system to capture stereo images of books was designed, including a page dewarping
algorithm using stereo vision. Since it is not possible to present the computationally very
expensive algorithm in real-time, a desing study and GUI demonstrator were created and
presented to a wider audience at the
CeBIT (Hannover, March 2005).
Our approach for stereo vision has been reconsidered and redesigned. The implementation
of a new stereo system for dewarping images of books is currently in progress.
|
| [Back to Top] |
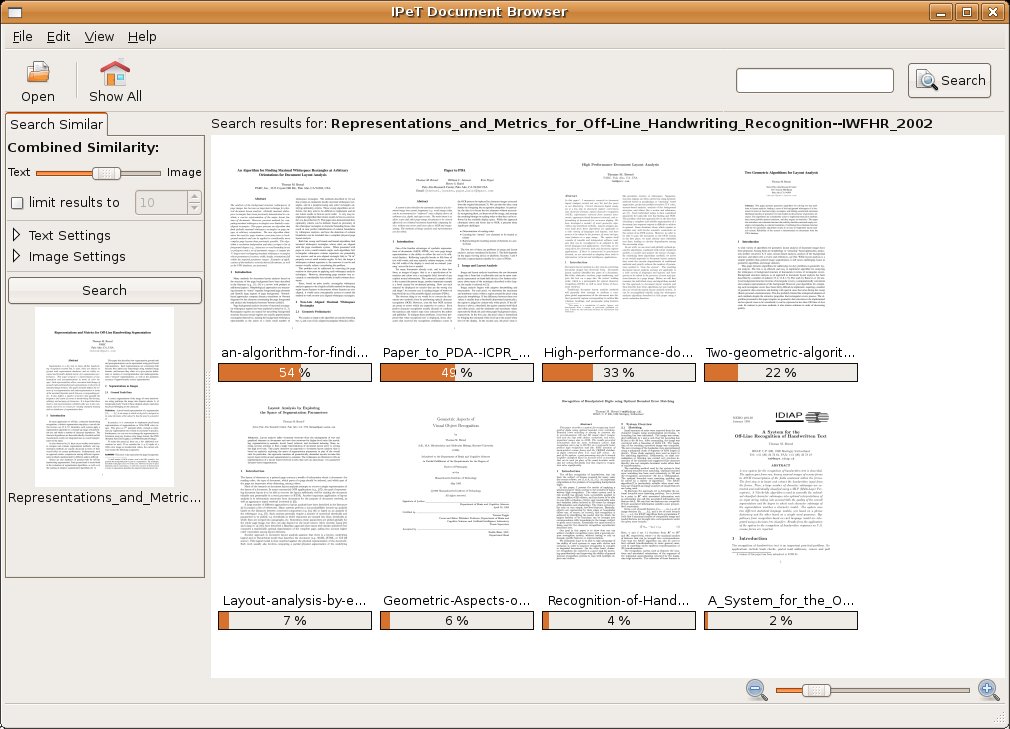
Document Browser
The main target of this demonstrator is to create a test-bed for user interface and systems
integration issues related to browsing of, information retrieval from, and search of large document
collections with heterogeneous representations (word processor filed, PDF, document images,
scans). A web-based document-browser is available as an on-line demo and continuously used by
the members of the IUPR research group to organize, search, and exchange research documents.
Its unique feature is the fall-back to OCR in the cases where the conversion of the electronically
uploaded document to text by other means fails.
The system was tested and evaluated for usability within our research group. As a result
of this process we obtained a stable system that is used within the group for the exchange and
search of relevant publications. Users can add files directly from a URL or from their file system,
thus continually enlarging and improving the database. It currently contains slightly more than
2000 research publications and supports the upload of documents in the formats of plain text,
PDF, PostScript, MS Word, and OpenOffice. Meta data (e.g. title, author, year, and keywords)
is extracted automatically from the submitted document text. If the automatic extraction of the
text fails (as for example some PDF documents do not allow the extraction of meaningful text),
the system uses a special layout-analysis tool combined with simple OCR. The resulting meta
data can then be edited manually. The saved documents are indexed and can be searched for
keywords, categories, and similar documents. The keyword and document search
employs Lucene, a mature open source search and index engine that fulfills all the Document
Browser's requirements. The basis for the keyword search is the tf-idf measure. For similar
documents we calculate the cosine distance.
A stand-alone application for document browsing is currently under development. The techniques
developped in this demonstrator can serve as a basis to enrich existing file system explorers
with document image understanding functionality.
|
|
The demo searches a collection of research papers.
|
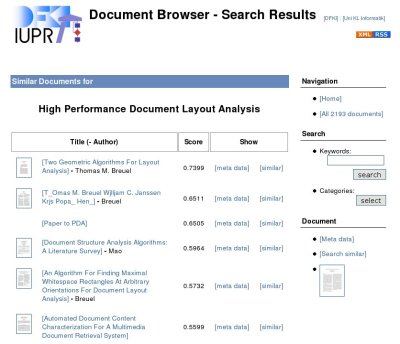
Screen shots of the document browser.
|
| [Back to Top] |
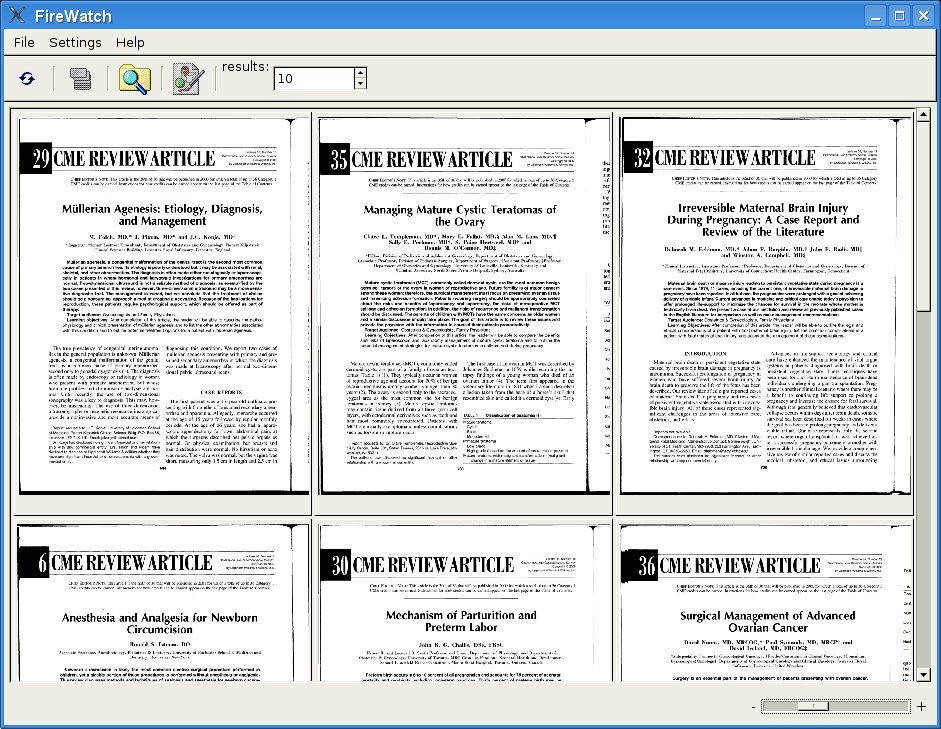
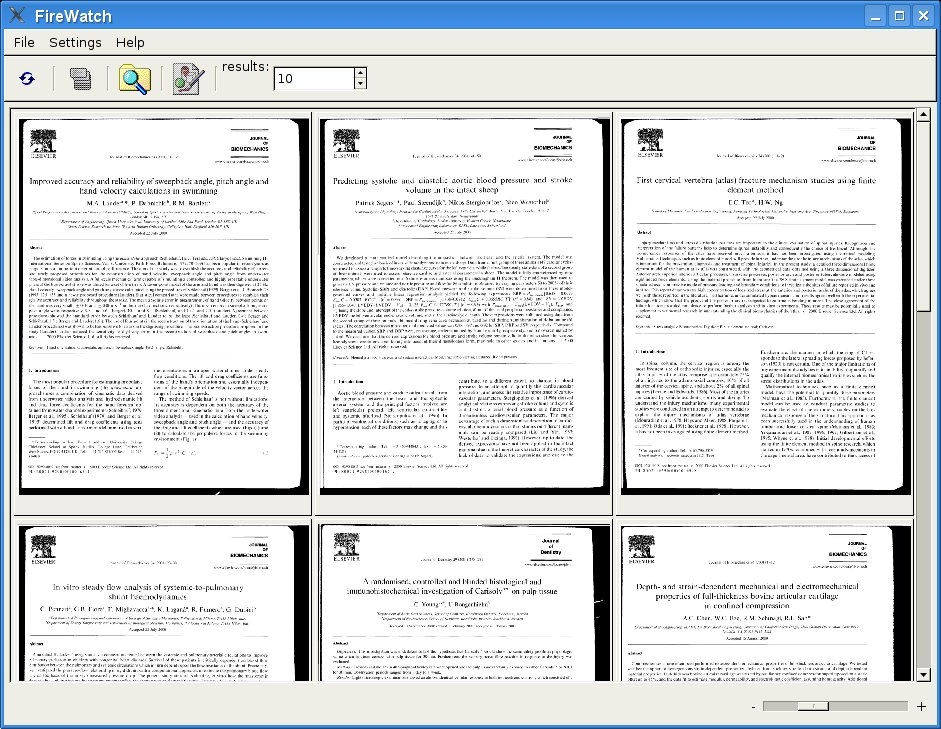
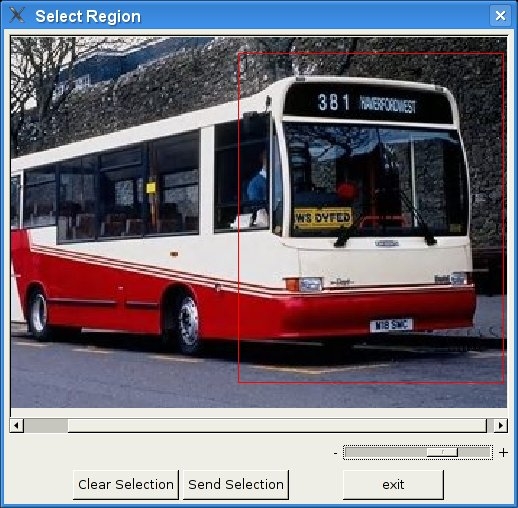
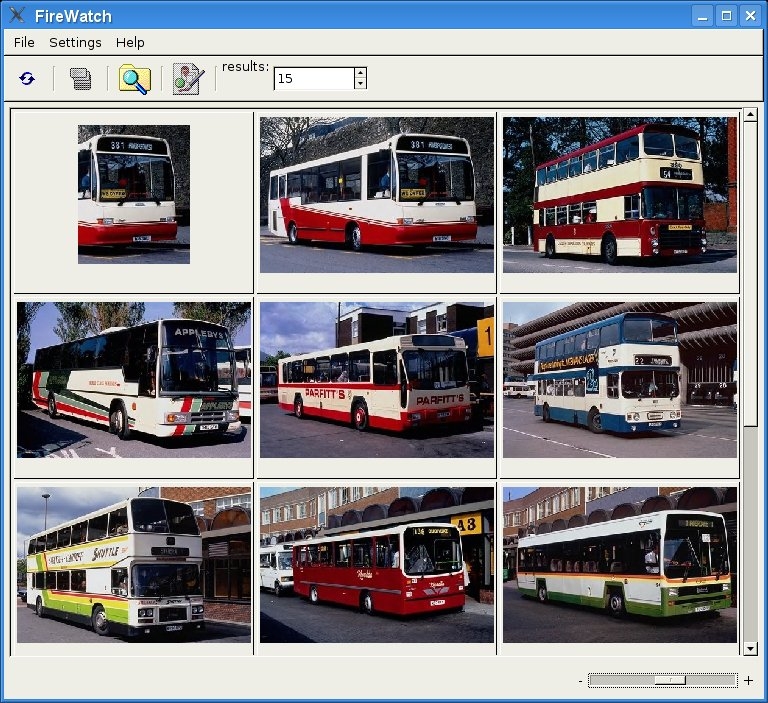
Visual document similarity search (FireWatch)
The search for similar documents is generally currently solved with keywords and meta-information.
This means, documents must be available in full-text versions or enriched manually with data.
The search for visually similar documents overcomes this need or can be used in addition to a
textual search.
The back-end of our approach is the open-source Flexible Image Retrieval Engine - FIRE,
because it allows easy integration of document-specific features. A web-based demonstrator
using the publicly available MARG database is available on-line.
We have also developed a stand-alone application called FireWatch, which can be used as a
client for the retrieval system. The user can choose between selecting an image from a random
set of images, selecting a region of an image, or uploading a new image. Then, similar images
from within the database are retrieved and shown. Figures show FireWatch with
example queries for document images and digital photos, respectively. FireWatch offers some
advantages in usability compared to the web-based FIRE client. First, the images can be viewed
more flexibly with a zoom slider and scrollbars, and second, the amount of displayed results can
be adjusted at any time. This software can also be seen as a prototype for the document and
image browsing applications which will be developed within IPeT.
|
|
Document Image Similarity Search allows you to search for visually similar document images in the MARG Database. The demo front-end is FIRE-Based.
|
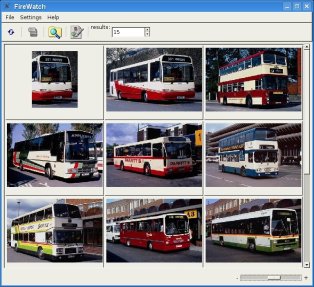
Search for visually similar documents in a document image database.
|

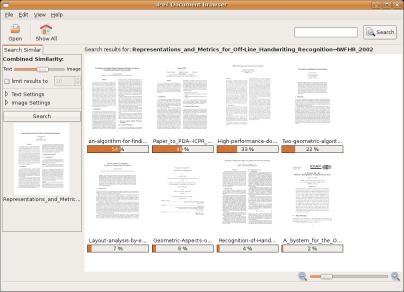
The FireWatch demonstrator showing retrieval of similar images by selecting a region.
|
| [Back to Top] |
Document Image Dewarping
Digital cameras offer a fast, flexible, cheap, and widespread alternative for the capture of documents.
Unfortunately, the acquired document images suffer –besides illumination and resolution
problems– from distortion. This is a severe problem especially when processing images of curled
book surfaces in which text-lines are nonlinear. While conventional dewarping
approaches try to estimate this surface and thus demand a complicated calibration process, we
developed a flexible snapshot-only approach.
The method is based on cell warping: letters and text lines are identified, and cells associated
with each letter are dewarped and rearranged on straight text-lines. A proper dewarp is made
possible by a pseudo-depth model of the page. For this, it is assumed that line spacing is
constant. Consequently, we measure the distance of adjacent text lines in the image and relate
it to the scene depth via fundamental laws of perspective projection. This yields a sparse
depth model of the document surface. The method works without any calibration – only a few
reasonable assumptions on camera parameters are made. Both planar and curled documents can
be coped with. Experiments showed that our dewarping does not only make document images
more readable, but also improves recognition rates of the OCR significantly.
To measure the performance of the different method for document image dewarping developed
in IPeT and to compare their performance, different quality measures for image dewarping
were developed.
|
|
The demo takes an image of a typical book page with curl and restores the original flat page image.
|


Dewarping of a page surface.
|

|

Dewarping of a crop of text.
|
| [Back to Top] |
One-step capture and restoration (OSCAR)
The largest class of printed information surrounding us is in planar document form, may it be
business cards, billboard signs, restaurant menus, car license plates, or slides of a presentation.
When captured with a digital camera, the images show perspective distortion making it necessary
to process them before extracting the textual information. However, for rectangular documents
it is possible to remove this distortion based on the image alone, without any a priori information
on the document or the camera. The OSCAR demonstration system was created to demonstrate
this possibility: for a document image, either supplied to the system in electronic form or
captured on the fly using camera-based document capture, it finds the best planar document
and dewarps it, keeping only the relevant document information and removing the surrounding
background. Figure shows two examples of dewarped slides of a presentation.
|
|
The demo finds the most prominent rectangular area in an image and returns that part after correcting the preojective transformation.
|


Two examples of dewarped captured slides of a presentation.
|
| [Back to Top] |
Geometric Layout Analysis
Page segmentation and reading order determination
In this context we have developed a complete layout analysis system. Given a document image
in any format, we perform layout analysis by first finding the gutters (whitespace separating the
columns of a document) in the image. Then, the text-lines respecting the columnar structure of
the document are found. Finally, the reading order of the text-lines is found using their spatial
relationships. Different steps of our layout analysis system are shown in the figure.
We have created an on-line demonstrator of our layout analysis algorithm. The user can
either submit a document image through the form interface, or can submit it programmatically
through HTTP. One can also submit a PDF document, in which case the first page is rendered
and layout analysis is performed. The result of the layout analysis is displayed as an image
inside the browser window.
Besides developing our own system for layout analysis, we performed a comprehensive evaluation
of various well-known algorithms for page segmentation, which is an integral part of
layout analysis. The results of applying different page segmentation algorithms to a test image
are shown in the figure.
|
|
The demo returns a color-image showing the results of the layout analysis part of the OCR for a given scanned document input image.
|




An example image showing different steps of our layout analysis system.
|
| [Back to Top] |
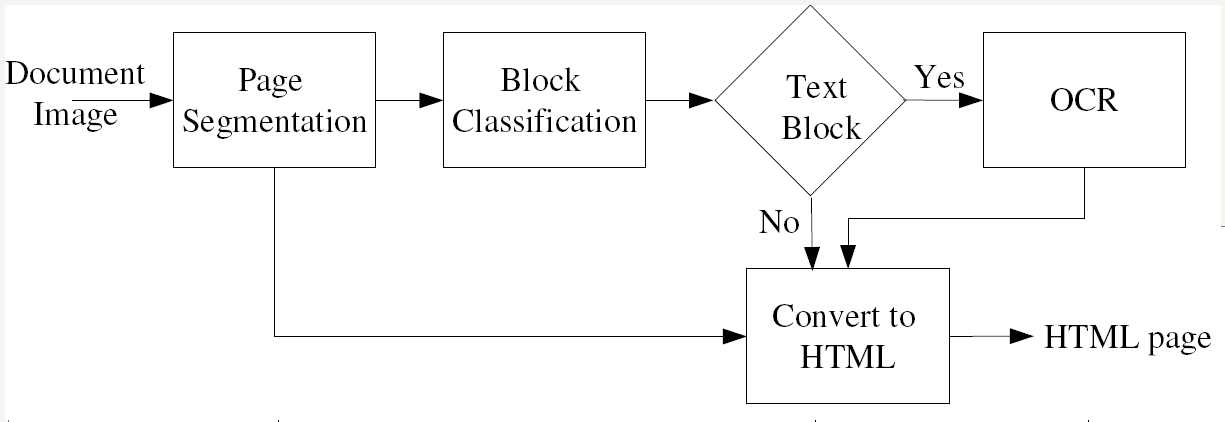
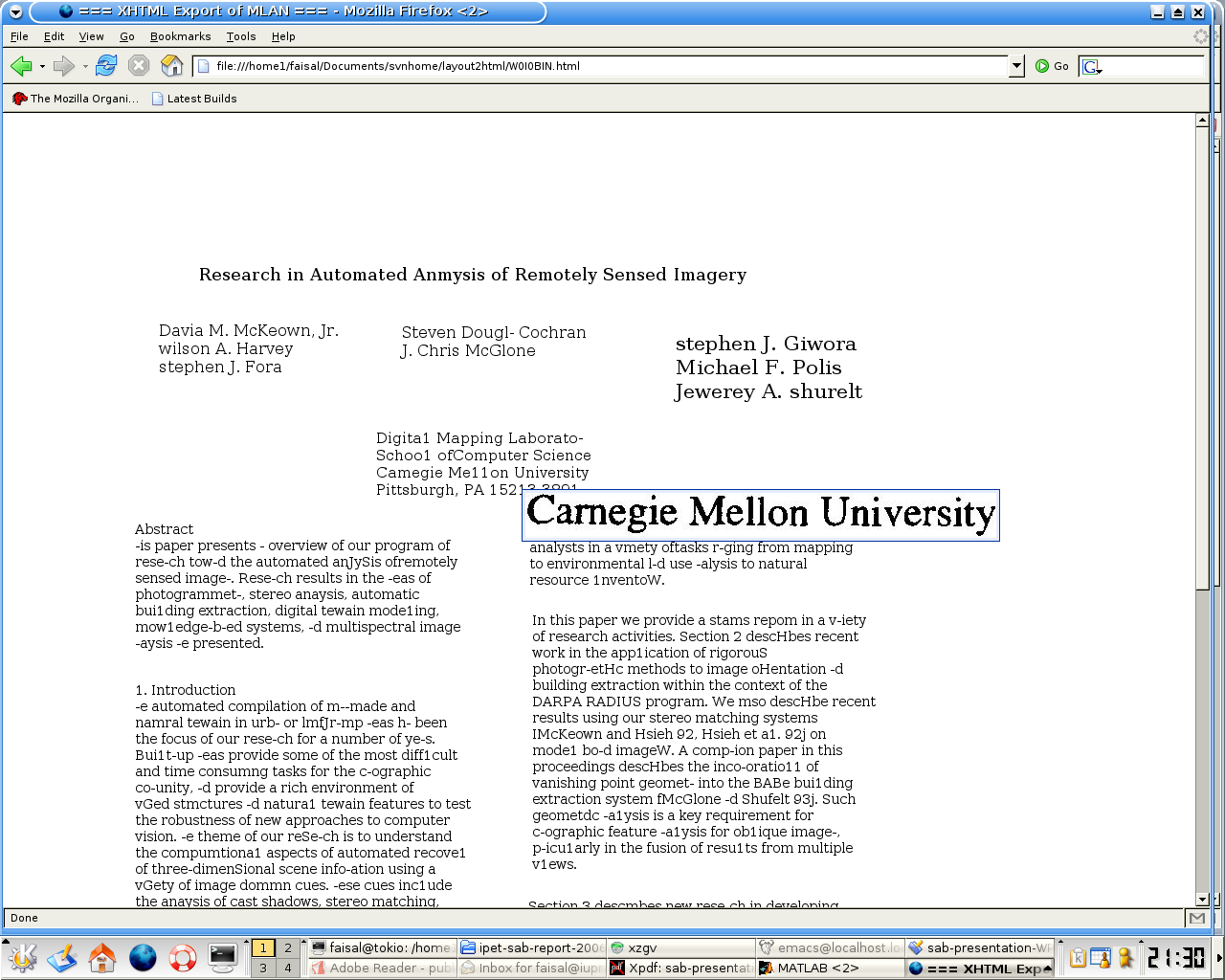
Document Images to HTML
A tool has been developed to convert document images to HTML. This tool is used to display
the result of the OCR and the layout analysis in a widely-spread format that also allows simple
sharing of documents. The tool uses the output of the OCR engine and the layout analysis to
build an HTML table that has the same layout as the original document. The block diagram
of our document image to HTML conversion utility is shown in the figure. A tool-tip-window
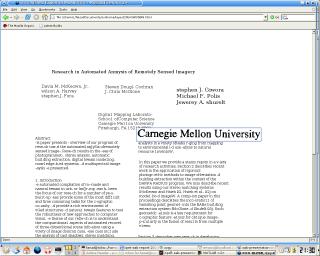
also displays the original image region to allow the user to check the OCR output. A screen
shot of a converted page is shown in the figure. The HTML document can also contain some
additional information such as the classifier confidence for each character. These information
could be visualized by labeling the characters with color. A screen shot of a converted page with
confidence information is shown in the figure.
|
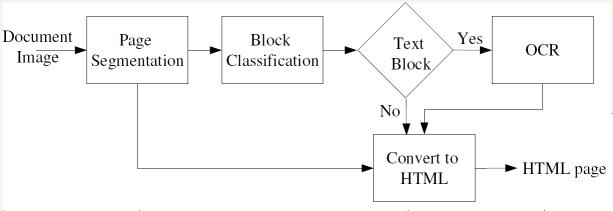
Block diagram of our document image to HTML conversion tool.
|


|
|
Screen shot of a scanned document converted to HTML with tool-tip displaying the
corresponding original image region.
|
|
|
Screen shot of a scanned document converted to HTML including classifier confidence
information (black: high confidence, blue: medium confidence, red: low confidence).
|
| [Back to Top] |
Comparison of Layout Analysis Techniques
The problem of automatic evaluation of page segmentation algorithms is becoming an increasingly
important issue. Major problems arise due to the lack of a common dataset, a wide
diversity of objectives, a lack of meaningful quantitative evaluation, and inconsistencies in the
use of document models. This makes the comparison of different page segmentation algorithms
a difficult task. We presented a quantitative comparison of six well-known algorithms for page
segmentation. The results showed that no single algorithm outperforms all other
algorithms and each algorithm has different strengths and weaknesses. Hence, it was suggested
that combining the results of more than one algorithm may yield promising results.
|






Results of applying different layout analysis techniques to an example image.
|
| [Back to Top] |
|
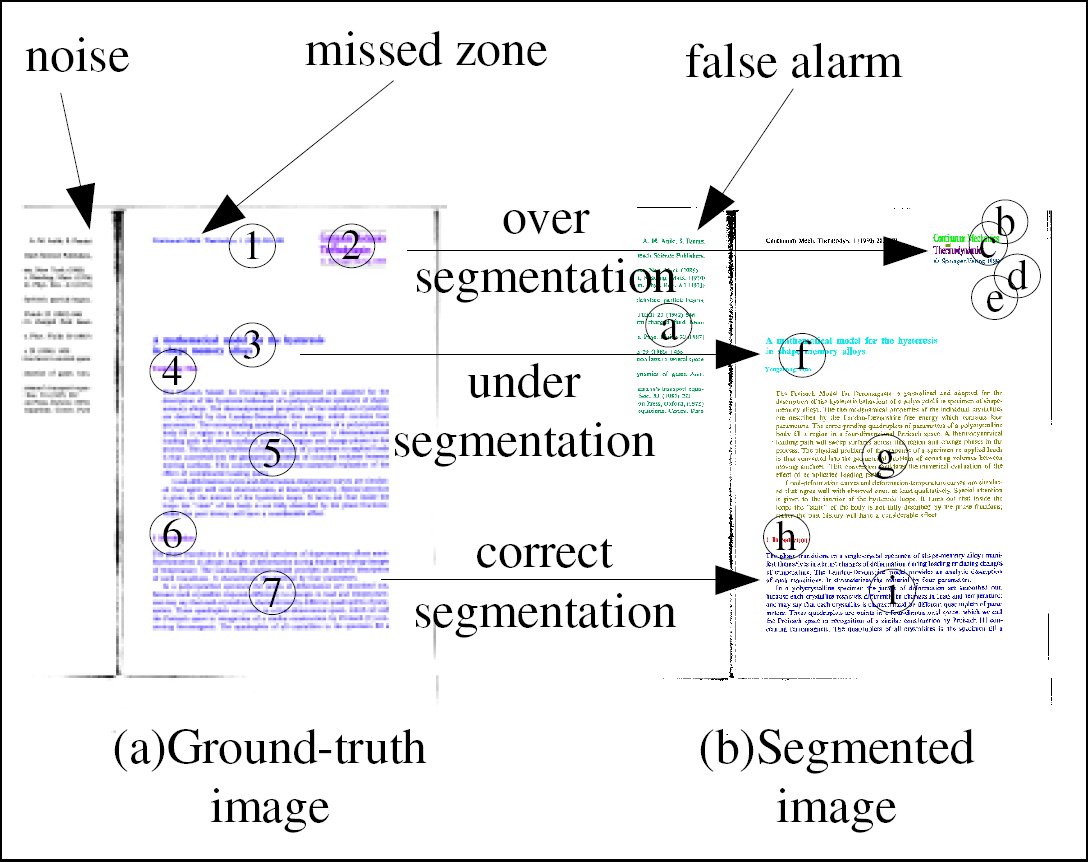
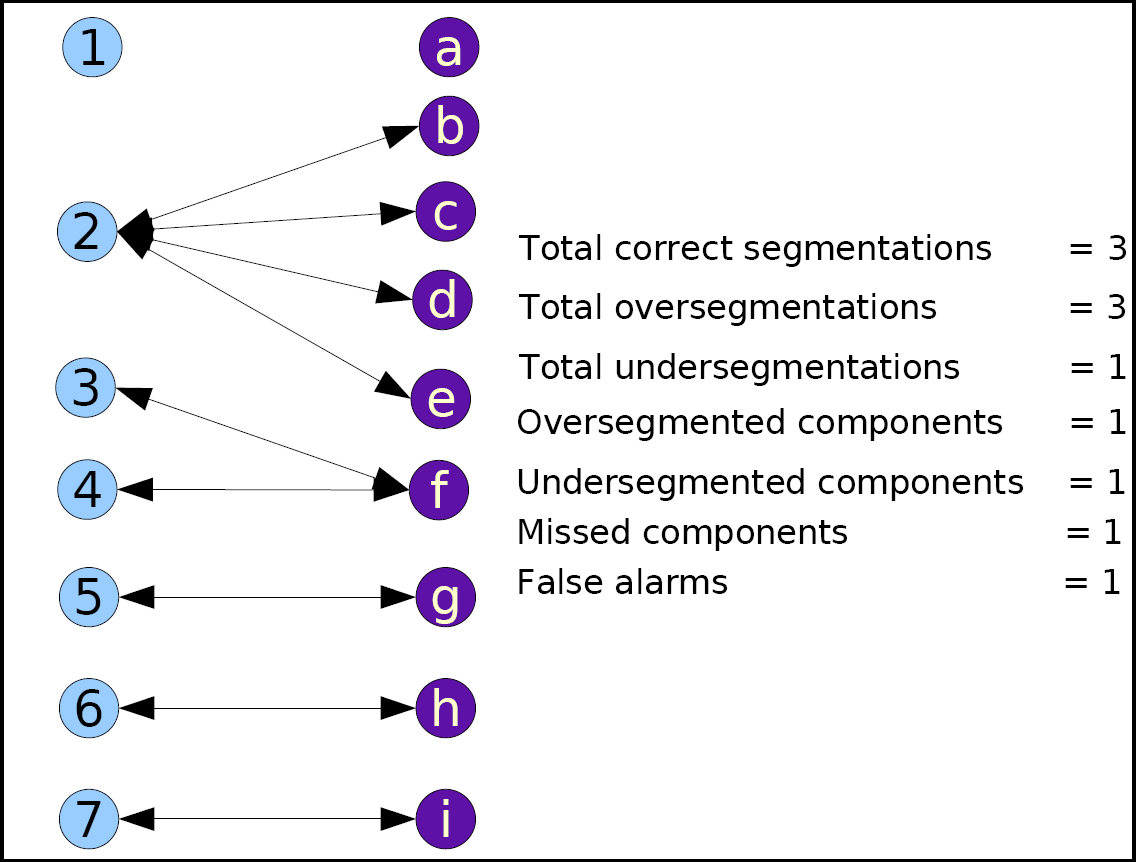
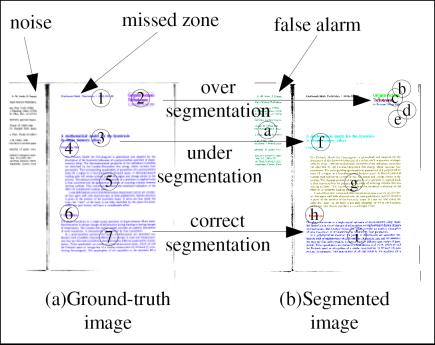
During the course of comparison, several limitations of the evaluation scheme were highlighted.
We addressed those limitations by developing a new pixel-accurate color-based representation
and evaluation scheme for page segmentation. The method permits a detailed analysis of the
behavior of page segmentation algorithms in terms of over- and under-segmentation at different
layout levels, as well as determination of the geometric accuracy of the segmentation. The
representation of document layouts relies on labeling each pixel according to its function in the
overall segmentation, permitting pixel-accurate representation of layout information of arbitrary
layouts and allowing background pixels to be classified as 'don't care'. Our representations can
be encoded easily in standard color image formats, permitting easy interchange of segmentation
results and ground truth. A set of new metrics are defined as shown in the figure to measure
different aspects of the segmentation algorithms quantitatively.
|
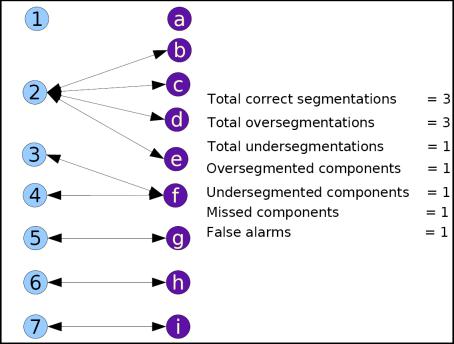
|
|
Example image to illustrate our new color-based representation of page-segmentation
and different error metrics defined.
|
| [Back to Top] |
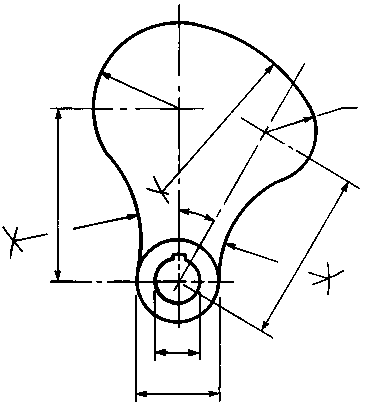
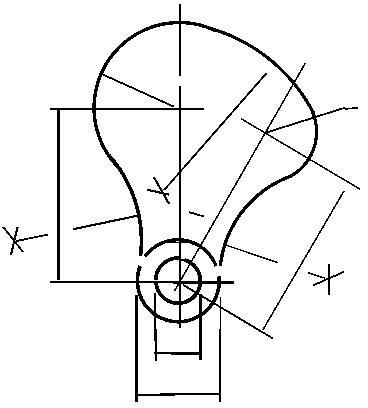
Geometric Matching for Arc and Line Finding
A large amount of technical and engineering information remains only available in paper form.
The goal of graphics recognition is to make that information available in electronic format. After
initial scanning, a key problem in the conversion of drawings into electronic form is the reliable
detection of the geometric primitives from which those drawings are constructed. We presented
a new solution to the problem of robust detection of lines and arcs in scanned documents or
technical drawings that works directly on run-length encoded data. The method finds globally
optimal solutions to parameterized thick line and arc models. Unlike previous approaches, it
does not require any thinning or other preprocessing steps, no computation of the line adjacency
graphs, and no heuristics. Furthermore, the only search-related parameter that needs to be
specified is the desired numerical accuracy of the solution. The method is based on a branchand-
bound approach for the globally optimal detection of these geometric primitives using runs
of black pixels in a bi-level image.
We used the 2003 GREC arc segmentation contest data to evaluate the approach. Using
the proposed method and the evaluation software corresponding to the contest, we obtained
a better score than published for the participating methods. We also participated
in the GREC 2005 arc segmentation contest, where we obtained the second place among the
three participating systems.
Existing systems for the detection of geometric primitives often include complex, hand-tuned
rules related to grouping, continuity, and plausible parameter ranges. If we identify such cases
or constraints, we can incorporate them into the quality function used by our algorithm. The
optimality guaranteed by the algorithm still holds (i.e., the algorithm will find the optimal
results under the improved quality function), as do the main advantages of the algorithm (few
parameters, strict separation of what is being optimized from the search algorithm itself).
|



|
|
Results for the detection of arcs and lines on the GREC 2003 data. Each row
shows (left to right): input, detected arcs and lines overlaid, detected lines, remaining runs not
explained.
|
| [Back to Top] |
Patch-Based Object Recognition Using Geometric Matching
The image object detection approach is based on a patch representation of images, which is
one of the state-of-the-art methods pursued in research today. Here, the combination with
geometric matching allows fast and accurate localization and recognition of objects in images
without segmentation based on given training examples.
We developed an efficient method to determine the optimal match of two patch-based image
object representations under translation, rotation, and scaling. This use of patches is equivalent
to a fully-connected part-based model, for which the approach offers an efficient procedure to
determine the best fit. By matching reference images that contain certain objects to a test image,
we can detect whether the test image contains an object of that class or not. We evaluated this
approach on the Caltech data and obtained competitive results (cp. Table).
The contribution of this work is to show that we can use a fully-connected part-based model
to solve the problem of patch-based object matching. Today, many successful approaches that
address the problem of general object detection use a representation of the image objects by
a collection of local descriptors of the image content, usually called patches or parts. This
paradigm has the advantage of being robust with respect to occlusions and background clutter
in images. Changes of the relative position of the patches to each other can be handled in
different ways and consequently various methods have been proposed in the literature.
The method developed within IPeT finds the optimal match of such a model in time linear in
the number of parts considered while some publications state that detection for a fully-connected
part-based model has exponential complexity in the number of parts. The reduced complexity in
the IPeT approach is possible, because the search is organized over the transformation parameter
space and simultaneously considers all parts. Note that this search organization is only feasible
because we implicitly factor the dependencies between the locations of the parts in the image into
the four components x-translation, y-translation, rotation, and scale. If we wanted to include
all general dependencies, the algorithm would effectively become exponential again, because of
the exponential growth of the search space with the number of parameters.
As proposed in the project plan, the next step in this research area will be to implement the
efficient search of the best-fitting prototype within a set of reference images by regarding the
bounds of match qualities for all images at the same time.
|


















|
|
Examples of objects recognized in images. Each group of three images shows (1) the
test image, (2) the best-fitting image from within the database of several hundred images, and
(3) the database image overlaid on the test image in the determined position.
|
| |
| Method | Airp. | Faces | Mot. |
| constellation model A | 32.0 | 6.0 | 16.0 |
| automatic segmentation | 2.2 | 0.1 | 10.4 |
| texture feature combination | 0.8 | 1.6 | 8.5 |
| constellation model B | 9.8 | 3.6 | 7.5 |
| PCA SIFT features | 2.1 | 0.3 | 5.0 |
| discriminative salient patches, SVM | 7.0 | 2.8 | 3.8 |
| spatial part-based model | 6.7 | 1.8 | 3.0 |
| constellation model C | 6.3 | 9.7 | 2.7 |
| patch histograms | 3.8 | 7.1 | 2.5 |
| features inspired by visual cortex | 3.3 | 1.8 | 2.0 |
| patch histograms+ | 1.4 | 3.7 | 1.1 |
| IPeT approach | 4.8 | 2.8 | 1.3 |
|
|
Table: Comparison of experimental results on the Caltech data (error rates [%]). (The references
are omitted here.)
|
| [Back to Top] |
Document Image Retrieval based on Layout Similarity
Most methods for document retrieval are based on textual information. However, when searching
for similar documents in a database, layout information can be a valuable supplement to textual
information, or even a substitute in its absence. This approach allows the user to search for
visually similar documents, e.g. to recover documents from the same journal, or documents with
the same layout type.
The distance measure developed within IPeT for this approach uses block information as
the description of layout. This is a two-step method which first computes distances from the
blocks of the query layout to the blocks of the reference layout. Then it matches the blocks of
the two layouts such that the smallest total distance is obtained. This distance is then used for
the retrieval process.
Various possibilities for the choice of block distance have been tested. Here, using the
overlapping area of two blocks was shown to be a good choice. For matching the blocks, three
different methods were tested, where the minimum weight edge cover matching performed best.
An example for a query layout and its best match is shown in the figure.
|

|
|
Example of layout-based document retrieval: the left-hand side contains the query
layout, the right-hand side the best matching layout.
|
| [Back to Top] |
Page Frame Detection
We developed a page frame detection system for document images, enabling us to remove textual
and non-textual noise from the document image. This type of noise occurs most often due to
copying or scanning processes at the borders of the document images. Figure shows results
of our system.
|



Some example results for page frame detection showing the detected page frames in
yellow.
|
| [Back to Top] |
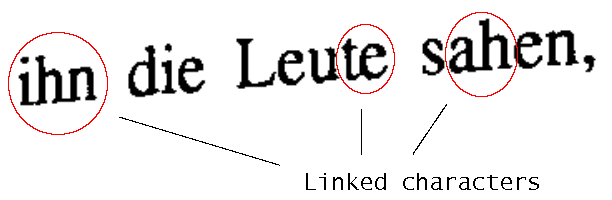
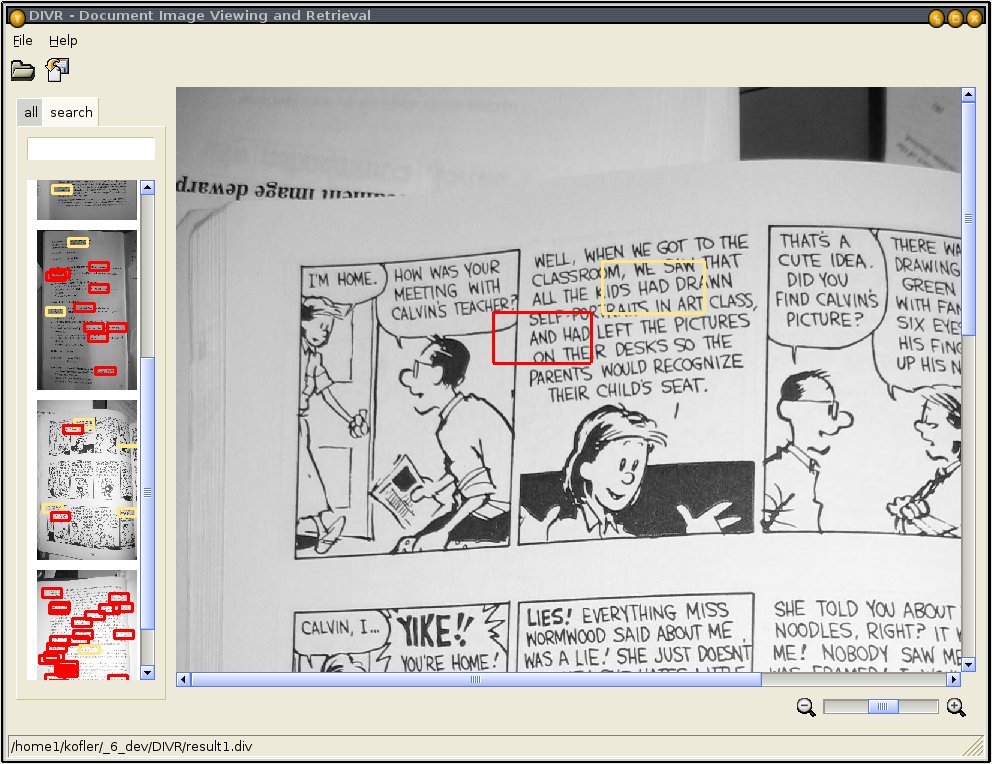
Document image viewing and retrieval based on special OCR (DIVER)
An alternative to dewarping a document image and then feeding it to a standard OCR engine is
to design an OCR system for the special needs of document capture using digital cameras. The
key problems coming with camera-captured document images are low resolution, character warp,
and linked letters. We face the first two problems by designing a
proper training set containing low-resolution and warped characters. Artificial generation using
a deformation model was tested as well as manual generation (using pictures of known letters
on curled document surfaces).
The method is applied in our demonstrator for searching text in document images captured
with handheld cameras called DIVER - Document Image ViEwing and Retrieval. The special
OCR algorithm extracts word hypotheses from the images and stores them along with the
corresponding bounding boxes. This processing is decoupled from the user interface and can be
performed in the background as separate task. The user can browse all loaded document images
in a list and search for keywords. DIVER is designed to cope with 'difficult' document images,
such as curled pages or pages containing uncommon fonts.
|


Character warping and linkage are key problems addressed by CamOCR.
|

GUI for the retrieval system using special OCR for difficult document images.
|
| [Back to Top] |
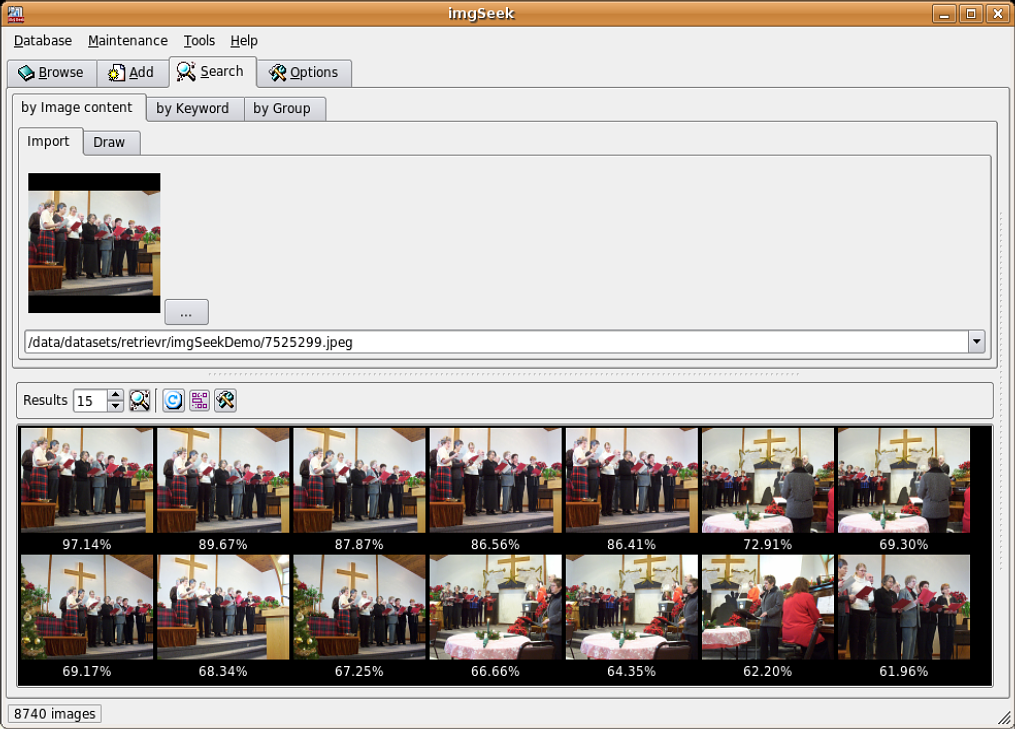
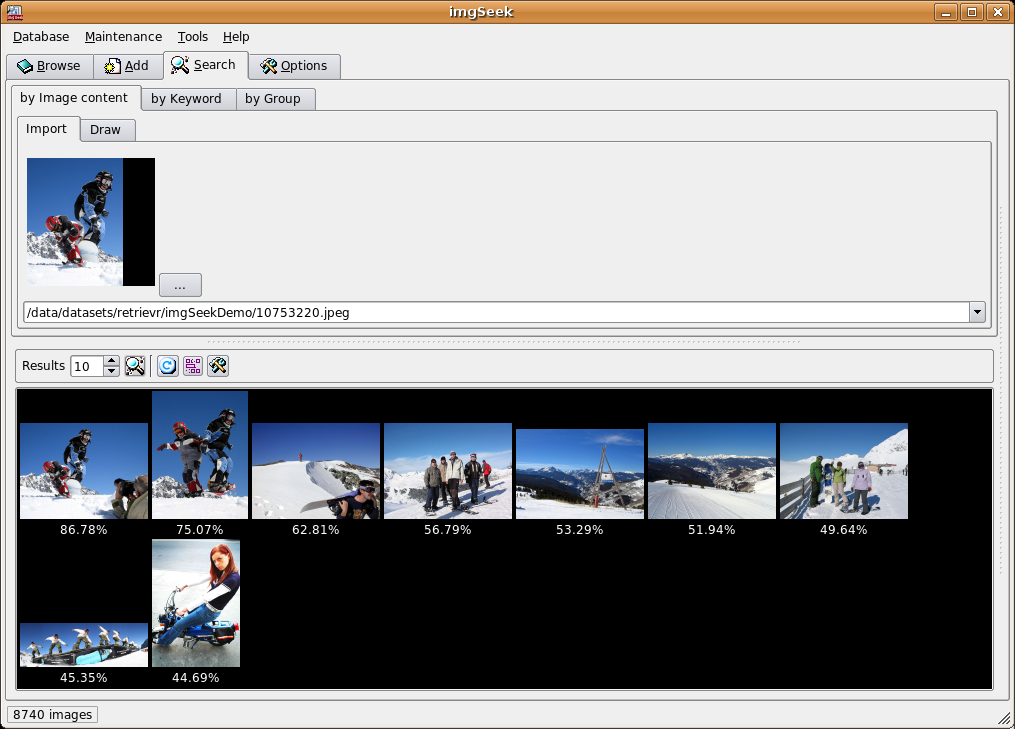
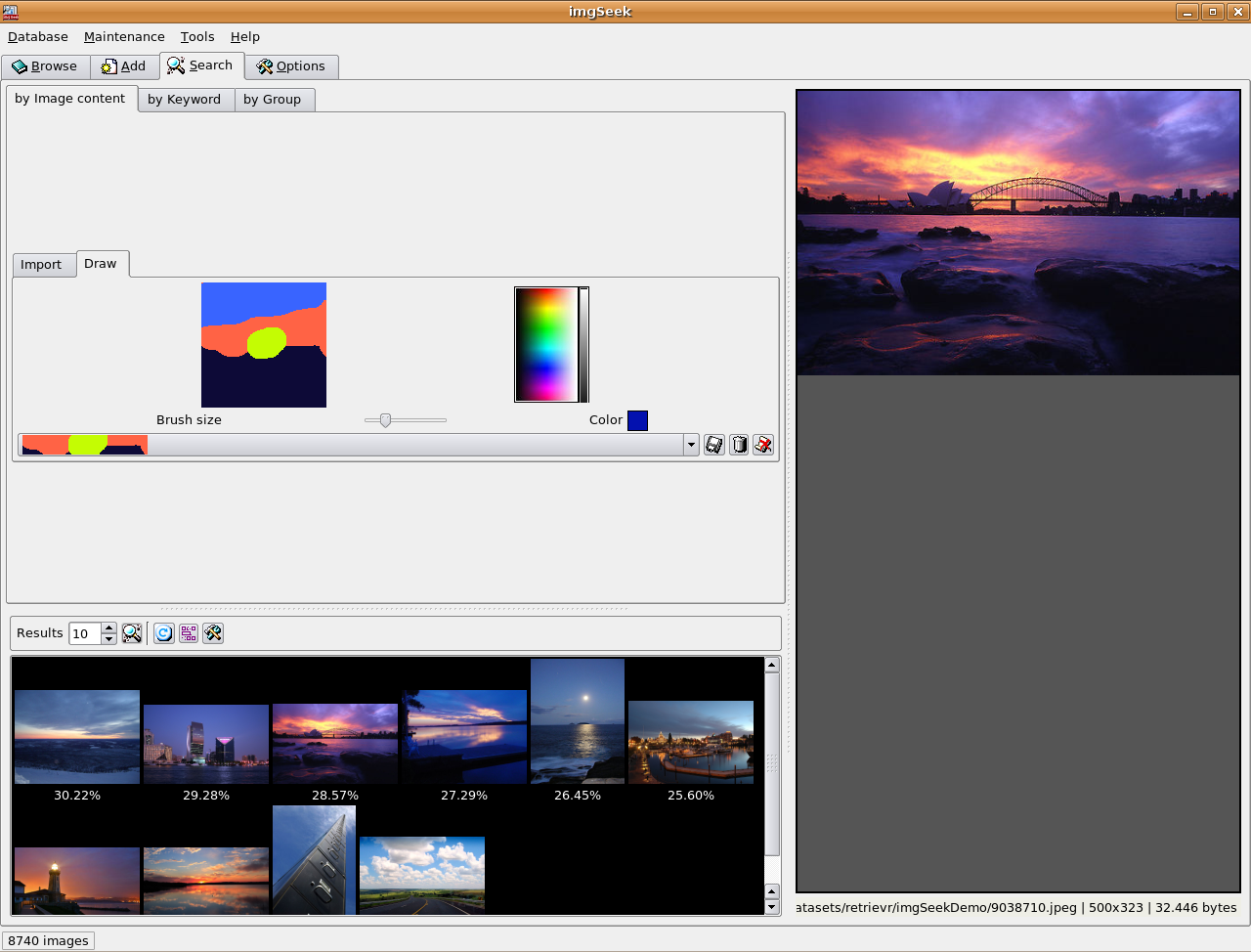
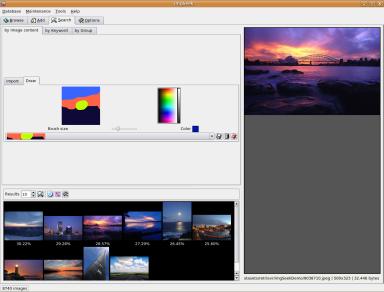
Image Browser
As a proof of concept, we have integrated our approach for image retrieval
into the open source application imgSeek. Among other features, the resulting demonstrator
allows for browsing an image collection, adding new images to it, retrieving images similar to
a sample image and drawing a sketch to retrieve similar images. We were able to significantly
increase the performance of the similarity search compared to the original version of imgSeek.
Figure shows two screenshots of our proof of concept.
|
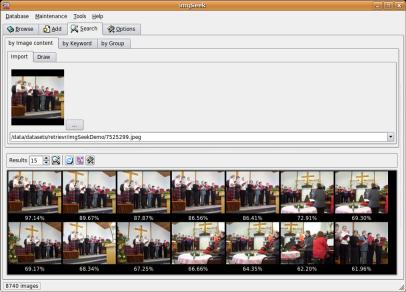
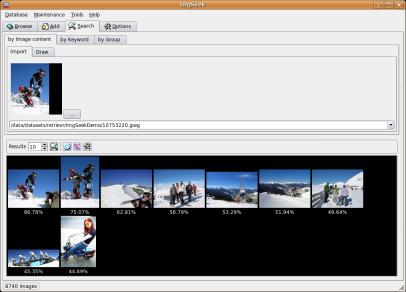
Two examples of search for similar images in imgSeek with our image retrieval approach.
|
Example of searhing for similar images using a sketch.
|
| [Back to Top] |
Bibliographic meta-data extraction using PFST
We have developed a system for Bibliographic Meta-Data Extraction from research paper references.
The system is based on Probabilistic Finite-State Transducers (PFST). Although finite-state techniques
have been utilized on various tasks of computational linguistics before they have not been used for the
recognition of bibliographic references yet. Especially the involved simplicity and flexibility of
modelling as well as the easy adaptability to changing requirements turn out to be beneficial. An
evaluation on the Cora dataset that serves as a common benchmark for accuracy measurements and
represents 'hard' cases yields a word accuracy of 88.5%, a field accuracy of 82.6% and an instance
accuracy of 42.7%, thus ranking our system second best with regard to the published results of
similar projects. The system is available as on-line demo at our demo web page.
|
|
The demo uses probabilistic finite state transducers. Input a scientific reference and the system will return a corresponding BibTeX entry.
|
| [Back to Top] |
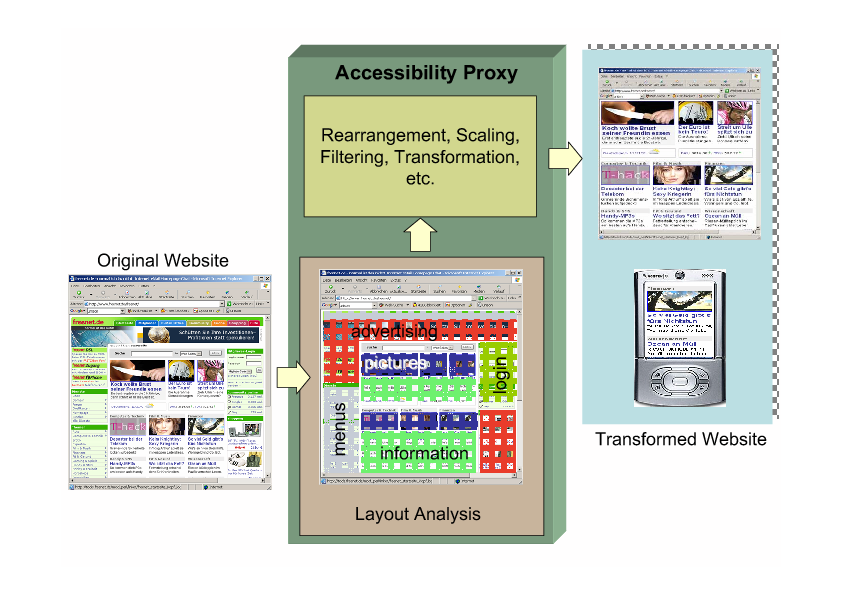
Accessibility Proxy
With its increased reliance on images, graphic design, and complex page layouts, the web is
increasingly difficult to use for the visually impaired. Even enabling a simple feature like the
"minimum font size" option will often end up making web pages unusable because it violates
design rules.
Image understanding techniques can be used to make such web pages accessible again. I.e.,
layout analysis can be used to determine which parts of web pages form logical layout units and
how those units can be rearranged, rescaled, and/or reordered. OCR can be used to capture the
textual content contained in images. And image understanding applied to diagrams and natural
scenes can summarize the content of other images (site graphs, headshots, scenery, product
shots, etc.).
We plan on demonstrating our technologies as part of an "Accessibility Proxy",
that is, a web proxy server that downloads HTML pages on behalf of a user, transforms
and annotates the HTML based on image understanding techniques, and presents the user with
a web page that can be understood more easily even as a purely textual page, or with very large
text sizes.
Such a web proxy is, of course, also closely related to proxies designed for displaying content
on small-screen, handheld devices, and our technologies may find applications in that area as
well, including transforming HTML to simplified XHTML for PDA display and automatically
transforming HTML to WML pages for display on cellular telephone displays.
We note that several systems performing such transformations already exist (e.g., from Netfront
and Danger). Our contribution will be the use of novel layout analysis and image understanding
methods to the field, which promise to improve the quality of the transformations.
|
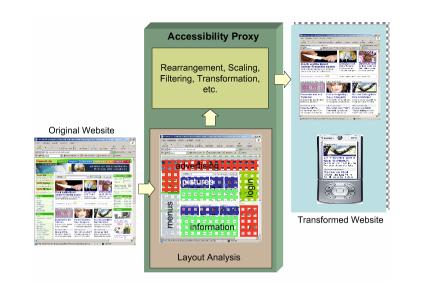
Accessibility Proxy Architecture
|
| |
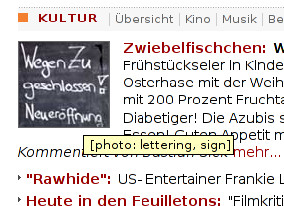
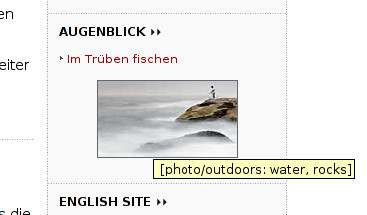
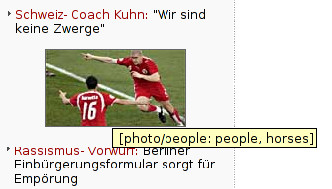

Example images showing the results of automatic image tagging using the Accessibility Proxy
|
| [Back to Top] |
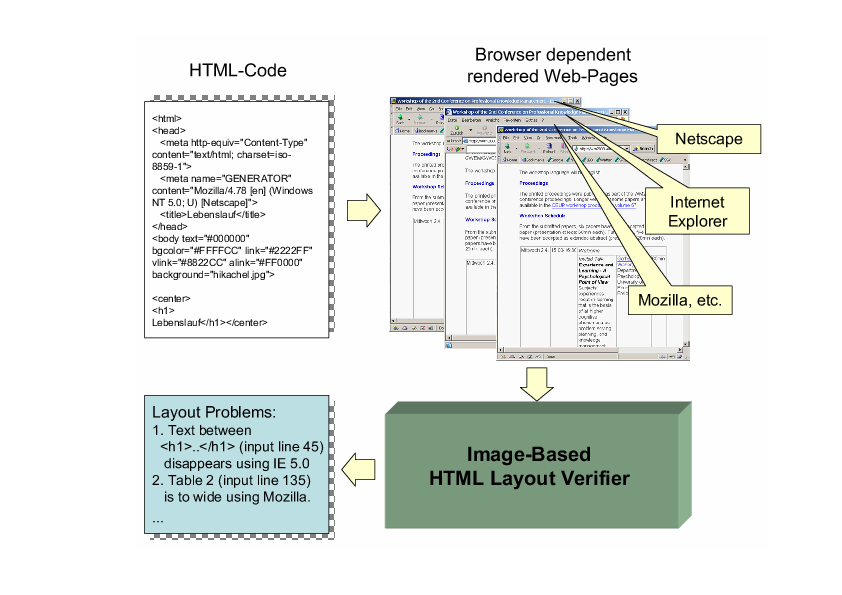
Image-Based HTML Layout Verifier
A significant practical problem with web pages (and other page layouts designed by non-experts)
is that they can be visually confusing and hard to read. Browser incompatibilities or changes in
the textual content may even make the output of a typesetting or page layout system defective,
meaning that text can disappear or end up overlapping.
If the page layout software (the browser, in this case) were under our control, such layout
verifiers could be integrated into its layout algorithms. That is, the browser itself could avoid
generating bad layouts by ensuring that design constraints are satisfied. (In fact, incorporating
such layout analysis functionality directly into the open source Mozilla browser may be a useful
project in itself.)
However, in the real world, the existence of dozens of different browsers is a given and a
page designer needs to create designs that work with each of the browsers and browser versions
that real users actually use. To help non-experts improve their designs to work with real webbrowsers,
we therefore plan on developing an image-based layout verifier based on our layout
analysis algorithms. That is, a tool that takes the image of a rendered web page
from different browsers and checks it for usable page layouts, readability, and visibility of all
textual content. This tool will combine the layout analysis tools and OCR tools to verify that
the HTML content is rendered acceptably. By being image-based, it can interface with all web
browsers (since images of their window contents can be obtained through browser-independent
operating system APIs).
This tool is currently under development. The rendering of a web page to image is done
using an extension of the open source Firefox browser, a commercial tool for IE and an open
source tool for Safari. The image is then binarized, followed by page segmentation and layout
analysis. Then the layout of the document is compared to the layout of the same web page rendered by a different browser. The matching of the layouts gives us the differences in the layouts as shown in the Figure below. In order to check the text readability of the rendered text, we process it through an OCR system to see which words are not readable.
|
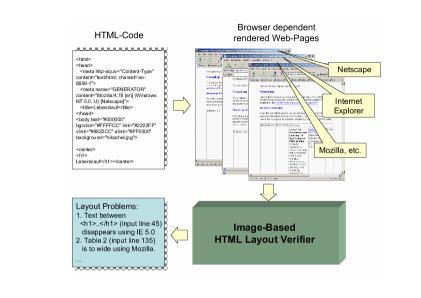
Image-Based HTML Layout Verifier architecture
|
| |
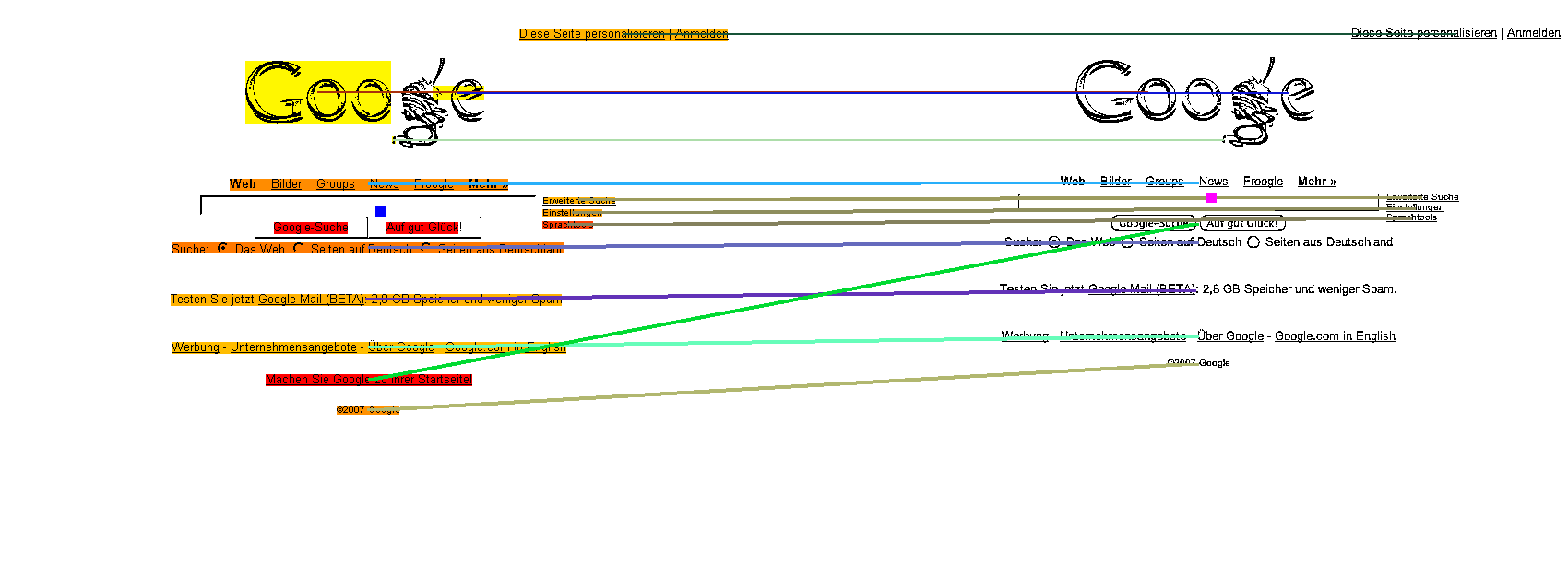

Layout matching of the Google homepage rendered by two different browsers. The image on the top shows the matching results of textlines in the image, while the bottom image highlights the differences in the layouts using the red color.
|
| |
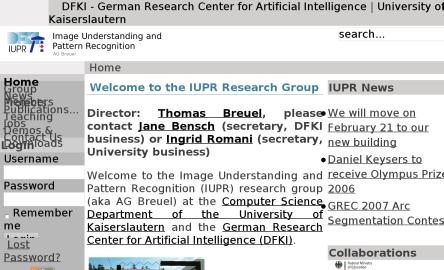

Text readability check for large font rendering. Unreadable (overlapping) text is highlighted with yellow color.
|
| [Back to Top] |